






В рубрику "Оборудование и технологии" | К списку рубрик | К списку авторов | К списку публикаций

Сбербанк, крупнейший банк в Центральной и Восточной Европе и один из лидеров по доступным клиентам цифровым сервисам, постоянно находится в фокусе внимания кибермошенников. Любые атаки в этом регионе всегда ориентированы в первую очередь на клиентов Сбербанка.
В банке реализована эшелонированная защита всех онлайн-услуг. Она включает в себя ряд защитных механизмов: подтверждение операций с помощью одноразовых паролей, шифрование трафика, использование встроенных антивирусных решений в приложениях и др. Один из ключевых элементов этой защиты – система выявления и предотвращения мошенничества (система фрод-мониторинга – ФМ).
В Сбербанке разработан и внедрен целый ряд моделей с использованием машинного обучения (Machine Learning) – ML-моделей, направленных на противодействие различным аспектам кибермошенничества (выявление мошеннических транзакций в разных каналах, мошеннических групп и их связей и др.), а также ансамбли из этих моделей. Это позволяет удерживать фрод на минимальных уровнях при постоянном росте транзакционной активности и появлении новых продуктов и услуг.
Подавляющее большинство работающих в промышленной эксплуатации моделей относятся к моделям "традиционной" архитектуры машинного обучения: байесовские сети, градиентный бустинг/Random Forest, логистические регрессии, обычные нейронные сети и др.
В данной статье мы рассмотрим менее традиционный для антифрод-индустрии метод, внедрение которого в наши модели противодействия мошенничеству дало существенный прирост эффективности.
Подавляющее большинство современных антифрод-решений включает в себя компоненты машинного обучения. Обычно эти компоненты в своей основе используют признаки, разработанные фрод-аналитиками и дата-сайентистами. Соответственно, чем лучше разработанные признаки позволяют описать мошенничество, тем выше эффективность моделей, их использующих.
Аналогично и в Сбербанке при разработке и развитии собственных моделей команда антифрод-экспертов регулярно анализирует тренды мошенничества, формулирует гипотезы и проверяет их. Результат – внедрение новых признаков, направленных на повышение эффективности моделей.
Но существуют и другие подходы, в которых на вход моделям подаются сырые данные, а они сами в рамках обучения выделяют значимые признаки. Наиболее известные представители такого подхода – модели Deep Learning, например сверточные (CNN) и рекуррентные (RNN) нейронные сети. В таких областях, как компьютерное зрение, распознавание речи и обработка естественного языка, эти решения превосходят все остальные подходы, включая традиционное машинное обучение.
Важно отметить, что во всех перечисленных областях (изображения, аудиозапись, текст) данные являются слабоструктурированными (Unstructured Data), тогда как задачи выявления мошеннических транзакций в целом решаются с помощью структурированных данных. Условно структурированные данные – это информация, которую можно представить в виде таблицы (строки – элементы наблюдения, столбцы – признаки). Сбербанк проводит эксперименты по применению CNN-и RNN-моделей в задаче выявления мошенничества.
Наряду с подходами Deep Learning есть и другие методы, позволяющие моделям самим создавать признаки. К таким подходам относится Entity Embedding – это обозначение целой группы ML-методов, с помощью которых можно представить различные сущности (например, слова, товары, клиентов) в виде вектора заданной размерности. Один из самых известных представителей данного класса методов – word2vec, применяемый в задачах обработки естественного языка (NLP).
Данный метод позволяет по имеющемуся корпусу текстов получить векторные представления слов. Полученные векторы обладают важным свойством: по расстоянию между векторами двух слов можно определить близость их значений. Под близостью в этом случае следует понимать сочетаемость слов. Кроме того, полученное векторное представление может улавливать некоторые семантические свойства слов. Пример из работы автора word2vec показан на рис. 1.
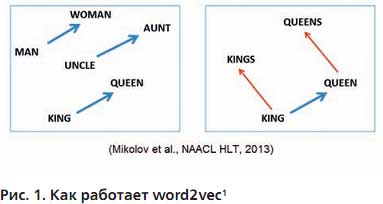
Если из вектора слова "женщина" вычесть вектор слова "мужчина", а затем к слову "король" добавить этот вектор разности (Female на рис. 2), то получим вектор, очень близкий к слову "королева". Также если из вектора слова "королева" вычесть вектор "женщина", а затем разность (Royal на рис. 2) вычесть из слова "король", то получим вектор близкий к слову "мужчина".
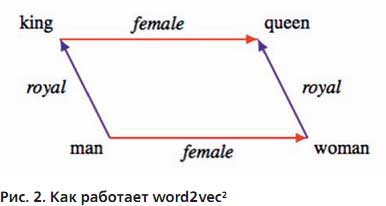
Есть также синтаксические связи – соотношения множественного и единственного чисел.
Вслед за успехом Embedding-подхода в NLP-задачах он стал применяться и в других областях, например в рекомендательных системах, где продукты также представлялись в виде векторов через схожие подходы. Еще одна область активного применения Embedding – кодирование категориальных признаков большой размерности.
В существенной доле мошеннических кейсов в качестве канала вывода средств используются банковские карты. Для эффективного противодействия таким кейсам фрода важно уметь определять "близость" клиента-отправителя и получателя (вероятность возникновения/типичность транзакций между такими клиентами). Клиент-отправитель в нашей задаче – это всегда клиент Сбербанка, клиент-получатель – это или клиент Сбербанка, если перевод осуществляется на карту Сбербанка, или же реквизиты карты стороннего банка. В последнем случае мы все равно будем отождествлять эту карту с некоторым неизвестным нам клиентом-получателем.
При разработке модели Entity Embedding (в нашем случае client2vec) мы ставили целью, чтобы итоговое векторное пространство в качестве "близости" как минимум уловило относительное геолокационное расположение клиентов, а как максимум – схожесть поведенческих паттернов. Полученные векторные описания и расстояние между ними будут использоваться в качестве дополнительных признаков в существующих моделях противодействия мошенничеству.
Может показаться, что вместо Entity Embedding можно ограничиться определением приблизительных геокоординат отправителя и получателя и использовать это расстояние в качестве признаков модели. Но этот подход сопряжен с рядом недостатков:
Кроме того, мы не получим векторного представления клиентов, которое также может нести дополнительную информацию, полезную для моделей ФМ.
Как мы увидим дальше, предложенный подход к созданию модели позволяет решить поставленную задачу без использования геолокационных данных и обойти указанные ограничения.
За основу была взята модель Continuous Bag of Words (CBOW), которая выступает одним из алгоритмов реализации word2vec и широко применяется в NLP-задачах.
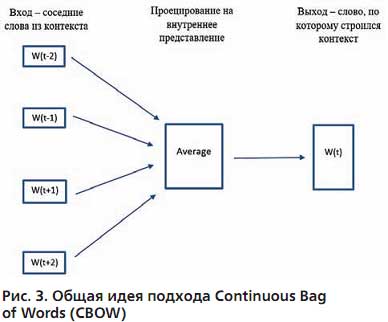
Суть алгоритма заключается в том, что мы по контексту слова пытаемся его предсказать (рис. 3). Например, для фразы "кошка высоко забралась на дерево" возьмем слово "забралась". Это будет наше слово w (t), тогда w (t - 2) = кошка, w (t - 1) = забралась, w (t + 1) = на, w (t + 2) = дерево. Модель учится предсказывать слово w (t) по его контексту, а результат работы модели – "сжатые" векторные представления слов (тот самый Embedding).
С математической точки зрения это реализуется через нейронную сеть с одним скрытым и выходным слоем. Для обучения модели все слова представляются в виде 1-Hot-Enco-ding (Input на рис. 4). 1-Hot-Encoding – вектор размерности, равной числу уникальных слов, где все координаты равны 0, кроме одной позиции, равной индексу этого слова в словаре. На этой позиции координата равна 1.
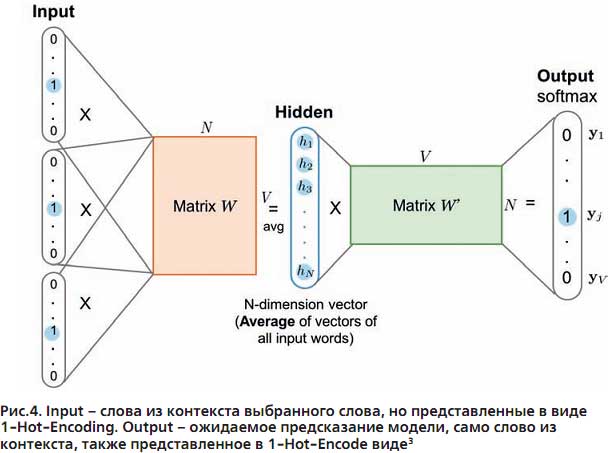
При обучении модели весовые коэффициенты внутреннего слоя сети (матрица W на рис. 4) оптимизируются, чтобы минимизировать функцию потерь (например, Cross-Entropy). Результатом работы такой модели становится матрица W, строки которой – векторные представления (Embedding) слов.
В рамках реализации подхода была также опробована модель GloVe (Global Vector), но ее результаты оказались хуже по сравнению со CBOW.
Для нашей задачи в качестве аналога слов в CBOW мы решили использовать ID банкоматов и устройств самообслуживания (обозначим их вместе как ATM) и ID физических платежных терминалов (POS), а в качестве аналогов предложений – упорядоченную во времени последовательность использования ATM/POS одним клиентом за определенный временной интервал (подбирался эмпирическим путем и в итоге составил 1,5 месяца). При этом была задействована дополнительная предобработка "предложений": если устройство-"слово" использовалось два или более раз подряд, то повторные использования удалялись, но если это устройство использовалось дальше после другого, то оно оставалось в выборке.
Пример предобработки последовательности использования ATM/POS:

Результатом работы такой модели будут векторные представления устройств-"слов" (POS/ATM), но для нашей задачи нам нужно получить векторное представление клиентов. Эмбеддинг клиента рассчитывался по алгоритму:
Для определения близости/ удаленности клиентов в полученном векторном представлении использовалось косинусное расстояние между векторами: Cosine Distance = 1 - Cosine Similarity.
Например, три клиента имеют следующие векторные представления: Иванов И.И. = (1,1,2.5), Петров П.П. = (1,1.2,2.1), Сидоров С.С. = (4, 0, 0.3). Тогда расстояние между Ивановым и другими двумя клиентами:
Из примера видно, что Иванов и Петров с точки зрения косинусного расстояния расположены гораздо ближе друг к другу по сравнению с Ивановым и Сидоровым.
Итоговая размерность "слов"/клиентов была выбрана равной 50 (а в примерах выше она была равна 3), в итоге каждому ID ATM/POS сопоставлялся вектор из 50 вещественных чисел. При их агрегации каждый клиент также был представлен вектором из 50 чисел. В рамках обучения и тестирования модели было опробовано еще несколько вариантов размерности, отличной от 50, но на этапе интеграции с моделью выявления мошеннических переводов результаты были хуже.
Анализ данных показал, что для покрытия более чем 90% всех ATM/POS (наш словарь, если говорить в терминах NLP) достаточно взять транзакции 20% клиентов в течение 1–1,5 месяцев. При этом отсутствие эмбеддинга по ряду ATM/POS не является проблемой, так как такие устройства-"слова" просто исключаются из "предложения" клиента, а оставшихся достаточно для формирования итогового векторного представления.
Было обучено две модели эмбеддинга. Одна – по указанному выше подходу на данных по транзакциям и клиентов, и не клиентов Сбербанка. А вторая – только по транзакциям клиентов Сбербанка, но в эту модель в качестве "слов" были добавлены также IP-адреса подсетей класса C, с которых клиенты пользовались интернет-банком.
Для быстрой валидации полученных векторных представлений устройств/IP-подсетей и проверки того, что векторные представления ухватили геолокационный паттерн, был использован следующий алгоритм: брался случайный ATM (банку известны их координаты установок) и искались ближайшие к нему соседние ATM по эмбеддингу. Точка и соседи визуализировались на карте по геокоординатам. Аналогично по этим же начальным точкам строились самые удаленные АТМ.

Процесс повторялся для нескольких десятков точек. Такая валидация позволила наглядно оценить, насколько близко/далеко на карте лежат друг к другу точки, которые близки/далеки на эмбеддинге.
Для анализа по IP-адресам сетей класса С с помощью алгоритма t-SNE была снижена размерность с 50 до 2 (для отображения векторного пространства на плоскости). IP-подсети раскрасили цветом в соответствии c территориальным банком Сбербанка большинства клиентов, которые используют данную подсеть. Видно, что в целом образуются хорошие локальные кластеры, а на долю операций IP-подсетей из центральной области (где множество разных цветов и кластер отсутствует) приходится менее 5% от всех операций.
В результате можно заключить, что векторные представления "слов" ухватили геолокационную сущность, особенно по ATM/POS, хотя никаких геопризнаков при обучении моделей не использовалось.
После обучения моделей и получения векторных представлений клиентов мы провели анализ того, насколько расстояние между векторными представлениями клиентов коррелирует с мошенничеством.
Для этого были взяты кейсы мошенничества (предотвращенные ФМ и успешные), а также ложные сработки системы ФМ за определенный период. Было подсчитано расстояние между векторными представлениями отправителя и получателя. Затем все кейсы были сгруппированы на основании полученных расстояний в группы – перцентили расстояний с шагом 10. В каждой группе подсчитано соотношение фродовых транзакций к легитимным (ложные сработки ФМ).
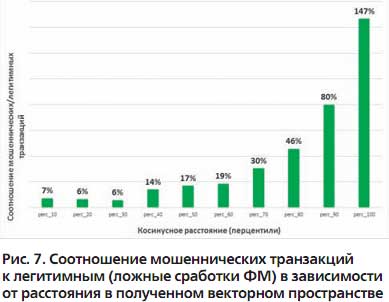
Результаты представлены на рис. 7. На нем отчетливо видно, что близость клиентов в полученном векторном пространстве снижает вероятность мошенничества, тогда как большое расстояние, наоборот, служит хорошим индикатором риска.
В результате применения описанного подхода нам удалось достичь запланированной цели: получено векторное пространство представления клиентов, в котором расстояние коррелирует с вероятностью мошенничества.
Векторные представления клиентов и векторные расстояния между ними были добавлены в качестве дополнительных признаков в Pipeline обучения моделей выявления мошеннических переводов.
По результатам обучения моделей ФМ векторное расстояние включено в итоговый перечень признаков как один из наиболее значимых. Кроме того, еще несколько признаков из векторных представлений клиентов также вошли в число значимых для модели.
Внедрение данных признаков позволило повысить общую эффективность системы выявления мошенничества – значительно сократить ложные сработки и одновременно немного увеличить долю выявляемого мошенничества. Наличие таких признаков особенно важно в условиях доминирующего сейчас типа мошенничества под условным названием "самопереводы". При их совершении клиент под воздействием мошенников, использующих методы социальной инженерии, сам переводит средства, и многие признаки антифрод-моделей (появление нового устройства, нестандартное время проведение операций и др.) в этом случае становятся неэффективными.
Полученные результаты еще раз свидетельствуют о том, что важно изучать современные методы машинного обучения из разных областей, так как при должном переосмыслении и транспонировании они могут успешно применяться и показывать хорошие результаты в других сферах.
Подобные исследования в подразделениях кибербезопасности Сбербанка будут активно продолжаться наряду с развитием традиционных моделей ML.
Опубликовано: Журнал "Information Security/ Информационная безопасность" #5, 2019

